doi: 10.56294/mr202466
ORIGINAL BRIEF
Enhancing the Identification of False News using Machine Learning Algorithms: A Comparative Study
Mejora de la identificación de noticias falsas mediante algoritmos de aprendizaje automático: Un estudio comparativo
Patakamudi Swathi1 *, Dara Sai Tejaswi1 *, Mohammad Amanulla Khan1 *, Miriyala Saishree1 *, Venu Babu Rachapudi1 *, Dinesh Kumar Anguraj1 *
1Koneru Lakshmaiah Education Foundation, Department of CSE, Vaddeswaram, Andhra Pradesh, India.
Cite as: Swathi P, Sai Tejaswi D, Amanulla Khan M, Saishree M, Babu Rachapudi V, Kumar Anguraj D. Enhancing the Identification of False News using Machine Learning Algorithms: A Comparative Study. Metaverse Basic and Applied Research. 2024; 3:66. https://doi.org/10.56294/mr202466
Received: 06-11-2023 Revised: 05-03-2024 Accepted: 28-04-2024 Published: 29-04-2024
Editor:
PhD.
Dra. Yailen Martínez Jiménez ![]()
ABSTRACT
In today’s digital world filled with information overload, preventing the rampant spread of fake news has become an urgent task. Discover the Fake News Prediction System (FNPS), which uses advanced machine learning and technology to provide innovative solutions and powerful methodologies. Natural language processing methods. FNPS uses sophisticated feature engineering from diverse, curated datasets to identify underlying patterns in fraudulent content and significantly improves the ability to recognize authenticity. FNPS achieves outstanding performance using a combination of classifiers combining TF-IDF vectorization, deep learning architecture, and sentiment analysis, demonstrating its ability to accurately predict the legitimacy of news articles. Beyond simple forecasting, FNPS provides an intuitive user interface for evaluating news content in real time. This not only increases accessibility but also promotes media literacy and responsible consumption of information. Provides additional information and promotes robust public discourse. FNPS essentially demonstrates the revolutionary potential of advanced technology in ongoing combat. This will further the important public goal of ensuring the reliability and integrity of information in the digital age.
Keywords: Machine Learning; Natural Language Processing; Feature Engineering; Deep Learning; Data Analytics; Algorithm Adaptation.
RESUMEN
En el mundo digital actual, repleto de sobrecarga de información, evitar la propagación desenfrenada de noticias falsas se ha convertido en una tarea urgente. Descubra el Sistema de Predicción de Noticias Falsas (FNPS), que utiliza tecnología y aprendizaje automático avanzados para ofrecer soluciones innovadoras y metodologías potentes. Métodos de procesamiento del lenguaje natural. FNPS utiliza una sofisticada ingeniería de características a partir de diversos conjuntos de datos curados para identificar patrones subyacentes en los contenidos fraudulentos y mejora significativamente la capacidad de reconocer la autenticidad. FNPS logra un rendimiento excepcional utilizando una combinación de clasificadores que combinan vectorización TF-IDF, arquitectura de aprendizaje profundo y análisis de sentimientos, lo que demuestra su capacidad para predecir con precisión la legitimidad de los artículos de noticias. Más allá de la simple predicción, FNPS proporciona una interfaz de usuario intuitiva para evaluar el contenido de las noticias en tiempo real. Esto no solo aumenta la accesibilidad, sino que también promueve la alfabetización mediática y el consumo responsable de información. Proporciona información adicional y fomenta un discurso público sólido. FNPS demuestra esencialmente el potencial revolucionario de la tecnología avanzada en el combate en curso. Con ello se fomenta el importante objetivo público de garantizar la fiabilidad e integridad de la información en la era digital.
Palabras clave: Aprendizaje Automático; Procesamiento del Lenguaje Natural; Ingeniería de Características; Aprendizaje Profundo; Análisis de Datos; Adaptación de Algoritmos.
INTRODUCTION
In the dynamic and ever-evolving digital environment of the 21st century, characterized by unprecedented flows of information through various digital platforms, the spread of misinformation, commonly referred to as fake news, poses a serious challenge. The deliberate dissemination of such false or misleading information permeates not only social structures but also individual perceptions, with serious consequences for public discourse, political processes, and the very structures of democratic governance. The democratization of information facilitated by social media platforms has fostered connections and information sharing, inadvertently creating a breeding ground for false narratives to spread quickly. These stories, often disguised as sensational or legitimate news, have profound effects, shaping public opinion, exacerbating social divisions and undermining trust in traditional institutions. In a complex situation where the line between truth and lies is blurred amidst a flood of digital content, the development of trustworthy content is essential. Tools to detect and mitigate the effects of fake news are becoming increasingly important. This imperative goes beyond simple technological innovation. In the digital age, protecting the integrity of information has become a social obligation that requires a collective effort. The problem of fake news is growing because the widespread spread of information through social media is unintentionally contributing to the rapid spread of false stories in society. This phenomenon permeates all aspects of social structure, from individual perceptions to wider social structures. As a result, our projects focus on finding innovative solutions based on cutting-edge technologies to address these multifaceted challenges. Recognizing the devastating impact disinformation has on democratic societies, we emphasize the need to develop tools to detect and mitigate its impact. Our commitment is to recognize the complexity of the fake news problem and adopt a multidimensional approach that integrates different disciplines of machine learning and natural language processing. The project is based on the integration of machine learning and natural language processing technologies, which allows it to analyze vast amounts of information and identify patterns indicative of fraudulent content. Using advanced algorithms and data analytics, our goal is to develop sophisticated tools that can adapt to new trends in deception tactics. Our vision is to create an informed, sustainable and alert society that goes beyond technological innovation and focuses on social well-being. Recognizing the urgent need to address the growing problem of fake news in the digital age, this project highlights the importance of detecting fake news in a digitally connected world. The ability to distinguish between trustworthy sources and misinformation is paramount to maintaining a well-informed population and promoting healthy public discourse. By developing powerful detection systems based on advanced machine learning technologies, we work to help people make informed decisions about the content they encounter. We use a subdomain approach that scrutinizes specific aspects of fake news detection, including feature engineering, natural language processing, and deep learning, to develop a comprehensive framework that can not only detect linguistic patterns indicative of fake news, but also interpret fake news. Create. We strive for this. These are basic semantic and syntactic clues that can be bypassed by rapid detection methods.
METHODS
Introduction to Context-Aware Framework
An introduction to context-sensitive frameworks. Amid the ongoing challenge of fake news, our project is leading the way in providing a situational awareness framework for detection. Recognizing the nuanced nature of the spread of misinformation, our approach goes beyond traditional methods by incorporating advanced situational analysis techniques. Central to our framework is the understanding that context plays an important role in the interpretation of information. By examining the temporal, spatial, and topical aspects of information dissemination, our system aims to improve the accuracy of fake news detection. This multifaceted approach not only recognizes the dynamic nature of language evolution over time, but also takes into account the geographic diversity and thematic contexts that shape the spread of misleading narratives. By integrating these contextual data, our framework aims to provide a more comprehensive understanding of fake news and help users make informed decisions in the face of a flood of digital information. As we advance the development of our situational awareness framework, we expect it to have a transformative impact on the fake news detection landscape. More than just a technological innovation, our project has the potential to increase society’s resilience to disinformation. By building a robust detection system based on contextual analysis, we aim to set a new standard for combating misleading narratives in the digital age. The outcomes we expect include not only the creation of complex technical solutions, but also proactive and informed solution development. A user base capable of critically evaluating the information they encounter. Through iterative improvements and continuous learning mechanisms, our systems strive to adapt to new fraud patterns and remain relevant and efficient in ensuring the integrity of information dissemination.
Fake News Detection and Feature Engineering
Identifying misleading content among vast amounts of digital information is a major challenge in today's information environment. This effort, called fake news detection, requires careful examination of textual content distributed across various media platforms. The search process depends on clearly recognizing the linguistic nuances and contextual clues that distinguish real news from misleading or fabricated information. Achieving this goal requires an interdisciplinary approach that combines concepts from feature engineering, natural language processing (NLP), and machine learning. Feature engineering is the cornerstone of this process of extracting and selecting information properties from text data. From lexical and syntactic properties to sentiment scores and semantic structures, these features provide input variables to machine learning algorithms. The effectiveness of the feature set directly affects the accuracy and reliability of the detection system, allowing it to recognize subtle patterns that indicate fake news.

Figure 1. Proposed NLP architecture for prediction
In the field of fake news detection, natural language processing (NLP) plays a key role in addressing the complexity of textual content. NLP techniques such as sentiment analysis, partofspeech tagging, and entity naming enable systems to extract contextual information, distinguish emotional tone, and identify key entities in news articles. These linguistic analyzes are combined with advanced machine learning algorithms to form the basis of modern detection systems. Among these algorithms, the Random Forest algorithm stands out for its versatility and efficiency. By creating multiple decision trees and aggregating predictions, Random Forest makes clever use of a diverse set of features extracted from text data. Its ability to handle highdimensional spatial features and avoid overfitting makes it a reliable tool for identifying deceptive patterns in textual content. Similarly, Support Vector Machines (SVMs) use kernel techniques to capture complex relationships in feature space, showing remarkable performance on both linear and nonlinear separable data. Additionally, the Multilayer Perceptron (MLP) neural network architecture excels at modeling complex relationships in high-dimensional feature spaces, providing adaptability and robustness for fake news detection.
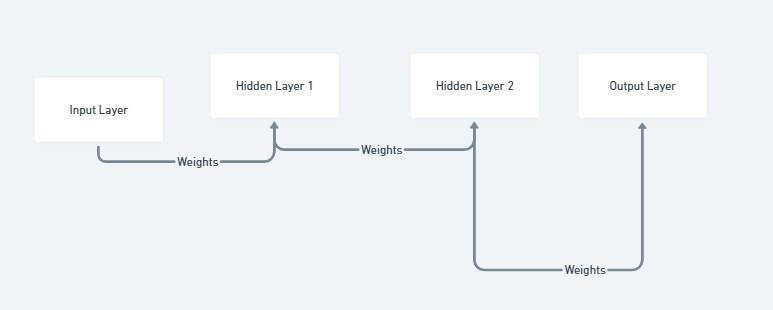
Figure 2. MLP architecture for fake news prediction
Support Vector Machine (SVM) is a powerful and adaptable classification algorithm known for its ability to manage both linear and non-linear separable data. Essentially, SVM attempts to determine the optimal hyperplane that maximizes the differences between individual classes in a data set, making it particularly suitable for distinguishing between real and fake articles in fake news detection scenarios where linear separation alone may not be sufficient. SVM uses kernel tricks to map the original feature space to a higher-dimensional kernel space, making it easier to capture complex and complex relationships that may be hidden in the original feature space. This is an important feature for identifying hidden patterns that indicate fake news. The ability to handle nonlinearity has proven invaluable in text classification, allowing SVMs to explore the intricate and complex feature space inherent in text data, making them a powerful tool for tasks such as fake news detection. Advantages of SVMs include efficiency in highdimensional spaces, providing versatility in kernel selection to handle different types of data, resistance to overfitting by maximizing margins, and the ability to handle non-linearly separable data. However, issues such as computational intensity, sensitivity to hyperparameters, and limited interpretability of decisions in high-dimensional spaces with complex kernels pose barriers to implementation. Internally, SVM contains components such as field optimization, support vector machines, hyperplanes, kernel tricks for high-dimensional operations, and various kernel functions that affect performance on different data sets.

Figure 3. SVM architecture for prediction
This paper investigates the application of three well-known machine learning models: support vector machines (SVMs), random forests, and multilayer perceptron’s (MLPs) in the context of fake news detection. Each model offers distinct advantages for analyzing text data and extracting patterns that indicate misinformation. SVM can handle both linear and nonlinear separable data using kernel methods that capture complex relationships. Random Forest excels at ensemble learning by efficiently using diverse feature sets extracted from text data. On the other hand, MLP uses hierarchical structures to model complex relationships in a high-dimensional feature space. Using this model, this paper aims to improve the accuracy and reliability of fake news detection systems using advanced machine learning techniques.
RESULTS
The experimental study conducted in this paper thoroughly evaluates the performance of a fake news detection system utilizing machine learning models. This process involves careful steps starting with data preprocessing, including loading the dataset, converting labels to binary format, and applying text normalization techniques such as lemmatization. Feature extraction techniques such as TF-IDF vectorization and vector word generation are used to prepare data for model training. This model has proven to be the most effective, demonstrating an excellent ability to distinguish between real and fabricated news articles. The comprehensive framework described in this article provides valuable insights into the effectiveness of machine learning models in detecting fake news, which has implications for increasing media trust and fighting disinformation in the digital age.

Figure 4. The Word cloud and EDA results of the news dataset
The evaluation of three different machine learning models for fake news detection revealed significant performance metrics. The multilayer perceptron classifier shows remarkable performance across a variety of metrics, including precision 0,87, precision 0,87, recall 0,86, and F1 score 0,86. The Random Forest classifier performs best, with precision of 0,90, precision of 0,91, recall of 0,88, and F1 score of 0,89. Similarly, Support Vector Machine (SVM) demonstrates robustness by achieving precision 0,88, precision 0,87, recall 0,86, and F1 score. 0,86. Additionally, the TF-IDF pipeline using linear regression achieves competitive results with precision of 0,85, precision of 0,84, recall of 0,83, and F1 score of 0,83. The evaluation includes ROC curves and AUC values, and the Random Forest classifier achieved an AUC of 0,94, indicating excellent discriminatory power. Overall, the Random Forest classifier was the most effective model, showing the highest accuracy and excellent precision, recall, and F1 score in distinguishing between real and fabricated news articles.
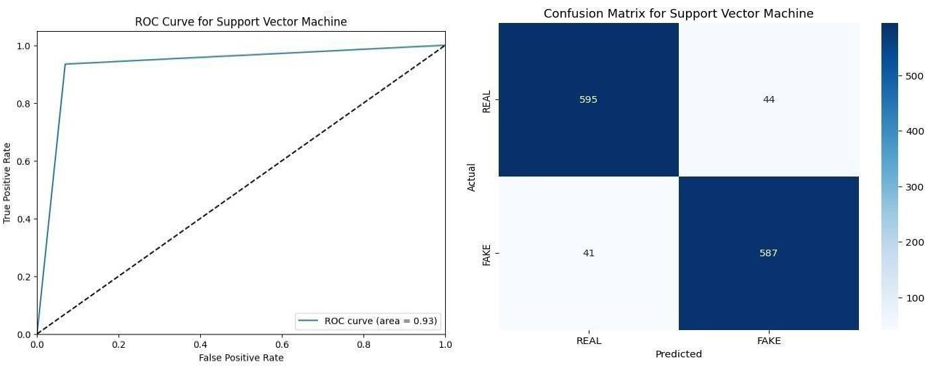
Figure 5. Confusion matrix and ROC Curve of model prediction
DISCUSSION
The project provides a strong foundation for future improvements and expansion and highlights potential areas for improvement and development. These areas include integrating additional sensory inputs such as touch or gesture recognition to improve interaction capabilities, implementing advanced signal processing algorithms to improve the accuracy and realism of the generated ECG-like signals, and adaptive learning and personalization. It uses machine learning algorithms to adapt to your personal preferences and voice patterns. Built-in real-time feedback mechanisms allow the system to dynamically adjust responses based on user feedback to provide a more personalized experience. The project also aims to extend the application to cover a wide range of scenarios, including modeling of different conditions and reactions, and provide seamless integration with external systems for comprehensive analysis and decision-making.
Literature
We conducted an extensive literature review to analyze existing research on this topic. In comprehensive fake news detection studies, researchers use advanced data mining techniques to closely examine the linguistic features, user behavior, and spread dynamics of social media platforms to identify patterns indicative of fake news.(1) Another study proposes a machine learning-based approach that emphasizes careful feature extraction from news articles and the key role of feature engineering in improving the performance of detection systems.(2) Other research uses natural language processing and sentiment analysis to create a framework that can distinguish between real and fake news, improving fake news detection and highlighting the importance of considering contextual information and linguistic subtleties for accurate classification.(3) Fake news detection has made significant progress with the introduction of machine learning-based frameworks that focus on extracting important features from news articles and highlighting the effectiveness of feature selection techniques to increase the accuracy of detection systems.(4) A thorough study of fake news detection investigates a wide range of machine learning algorithms, highlighting the importance of model selection and evaluation metrics in developing robust detection systems and positioning this work as a practical and valuable contribution to the field.(5,6,7,8) Lilapati Vaikhom et al.(6) explored machine learning techniques for fake news detection using feature extraction, sentiment analysis, and classification algorithms to recognize fraudulent content. Their methodological approach, including ensemble methods, demonstrated a comprehensive strategy to position their research as a valuable resource in the face of the complexities of fake news. Murari Choudhary et al.(7,9,10,11,12) thoroughly reviewed fake news detection methods, including feature engineering, sentiment analysis, and ensemble analysis. Educate and provide information about the strengths and weaknesses of each approach and encourage a variety of approaches. Arun Nagaraja et al.(8) Machine learning techniques for fake news detection have been studied with a focus on model interpretability and explainability to improve the reliability of detection systems. Julio K.S. Reis et al.(9) focused on explainable machine learning techniques to improve model interpretability and user confidence in classification results. Sachin Kumar et al.(10) presented a novel approach that uses deep learning models to automatically identify subtle linguistic clues indicative of fake news, highlighting the potential of deep learning in this field and paving the way. The road to sophisticated detection systems. Chaitra K. Hiramath et al.(11,13,14,15) used Deep to improve fake news detection.(16,17,18,19) A learning method that focuses on deep neural networks to extract high-level features from news articles and exploit linguistic complexity. The use of deep learning shows the potential to improve classification accuracy, setting a precedent for future efforts. Aayush Ranjan(12) has made a significant contribution to this field by conducting a comprehensive study on feature engineering, model selection, and evaluation metrics, providing useful information for building robust detection systems. Sheng Hou Kong et al.(13) made remarkable progress by applying deep learning and using convolutional neural networks (CNNs) to capture complex linguistic patterns indicative of fake news, thereby revolutionizing approaches in this field.(20,21,22)
CONCLUSION
The success of the fake news detection project can be attributed to the careful evaluation of different machine learning models that demonstrate their unique ability to distinguish between real and fabricated news articles. The multilayer perceptron classifier (MLP) demonstrated strong performance with an accuracy of 87 % and notable precision, recall, and F1 score values. The Random Forest classifier took first place with an impressive accuracy of 90 % and high precision, recall, and F1 score, as well as an impressive area under the ROC curve (AUC) of 0,94. Support Vector Machine (SVM) also made significant contributions, providing commendable accuracy and performance. Additionally, the TF-IDF pipeline using linear regression showed competitive results. Overall, the careful evaluation and integration of various machine learning models, of which the Random Forest classifier stands out, highlights its ability to accurately detect fake news and combat disinformation in the digital age.
REFERENCES
1. Shu, Kai, et al. "Fake news detection on social media: A data mining perspective." ACM SIGKDD explorations newsletter 19.1 (2017): 22-36.
2. Khanam, Z., et al. "Fake news detection using machine learning approaches." IOP conference series: materials science and engineering. Vol. 1099. No. 1. IOP Publishing, 2021.
3. Shaikh, Jasmine, and Rupali Patil. "Fake news detection using machine learning." 2020 IEEE International Symposium on Sustainable Energy, Signal Processing and Cyber Security (iSSSC). IEEE, 2020.
4. Baarir, Nihel Fatima, and Abdelhamid Djeffal. "Fake news detection using machine learning." 2020 2nd International workshop on human-centric smart environments for health and wellbeing (IHSH). IEEE, 2021.
5. Sharma, Uma, Sidarth Saran, and Shankar M. Patil. "Fake news detection using machine learning algorithms." International Journal of Creative Research Thoughts (IJCRT) 8.6 (2020): 509-518.
6. Waikhom, Lilapati, and Rajat Subhra Goswami. "Fake news detection using machine learning." Proceedings of International Conference on Advancements in Computing & Management (ICACM). 2019.
7. Choudhary, Murari, et al. "A review of fake news detection methods using machine learning." 2021 2nd International Conference for Emerging Technology (INCET). IEEE, 2021.
8. Nagaraja, Arun, et al. "Fake news detection using machine learning methods."
9. International Conference on Data Science, E-learning and Information Systems 2021. 2021.
10. Reis, Julio CS, et al. "Explainable machine learning for fake news detection." Proceedings of the 10th ACM conference on web science. 2019.
11. Kumar, Sachin, et al. "Fake news detection using deep learning models: A novel approach." Transactions on Emerging Telecommunications Technologies 31.2 (2020): e3767.
12. Hiramath, Chaitra K., and G. C. Deshpande. "Fake news detection using deep learning techniques." 2019 1st International Conference on Advances in Information Technology (ICAIT). IEEE, 2019.
13. Ranjan, Aayush. Fake news detection using machine learning. Diss. 2018.
14. Kong, Sheng How, et al. "Fake news detection using deep learning." 2020 IEEE 10th symposium on computer applications & industrial electronics (ISCAIE). IEEE, 2020.
15. Pal A, Pranav, Pradhan M. Survey of fake news detection using machine intelligence approach. Data & Knowledge Engineering 2023;144:102118. https://doi.org/10.1016/j.datak.2022.102118.
16. Prabha C, Malik M, Kumari S, Arya N, Parihar P, Singh J. Detection of fake news: A comparative analysis using machine learning. AIP Conference Proceedings 2024;3072:040014. https://doi.org/10.1063/5.0198691.
17. Villela HF, Corrêa F, Ribeiro JS de AN, Rabelo A, Carvalho DBF. Fake news detection: a systematic literature review of machine learning algorithms and datasets. Journal on Interactive Systems 2023;14:47-58. https://doi.org/10.5753/jis.2023.3020.
18. Capuano N, Fenza G, Loia V, Nota FD. Content-Based Fake News Detection With Machine and Deep Learning: a Systematic Review. Neurocomputing 2023;530:91-103. https://doi.org/10.1016/j.neucom.2023.02.005.
19. Yenkikar A, Sultanpure K, Bali M. Machine learning-based algorithmic comparison for fake news identification. AI-Based Metaheuristics for Information Security and Digital Media, Chapman and Hall/CRC; 2023.
20. Ahmed N, Rawat M. A review on identification of fake news by using machine learning. Artificial Intelligence, Blockchain, Computing and Security Volume 1, CRC Press; 2023.
21. Sudhakar M, Kaliyamurthie KP. Detection of fake news from social media using support vector machine learning algorithms. Measurement: Sensors 2024;32:101028. https://doi.org/10.1016/j.measen.2024.101028.
22. Jindal H, Mangla M, Singh G. Fake News Detection Using Machine Learning. En: Roy NR, Tanwar S, Batra U, editores. Cyber Security and Digital Forensics, Singapore: Springer Nature; 2024, p. 375-85. https://doi.org/10.1007/978-981-99-9811-1_30.
FINANCING
The authors did not receive financing for the development of this research.
CONFLICT OF INTEREST
The authors declare that there is no conflict of interest.
AUTHORSHIP CONTRIBUTION
Conceptualization: P.Swathi, D.SaiTeja, MD.Aman, M.Saishree.
Data curation: P.Swathi.
Formal analysis: D.SaiTeja.
Acquisition of funds: None.
Research: P.Swathi, D.SaiTeja, MD.Aman, M.Saishree.
Methodology: P.Swathi, D.SaiTeja, MD.Aman, M.Saishree.
Project management: P.Swathi, D.SaiTeja, MD.Aman, M.Saishree.
Resources: M.Saishree.
Software: MD.Aman.
Supervision: R.Venubabu, A.DineshKumar.
Validation: R.Venubabu, A.DineshKumar.
Display: P.Swathi, D.SaiTeja, MD.Aman, M.Saishree.
Drafting - original draft: P.Swathi, D.SaiTeja, MD.Aman, M.Saishree.
Writing - proofreading and editing: P.Swathi.